Lab 4 - Python Code#
Authors: Valerie Dube, Erzo Garay, Juan Marcos Guerrero y Matias Villalba
Bootstraping#
import pandas as pd
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
import seaborn as sns
Data base#
The data is not created randomly; it is extracted from the “penn_jae.dat” database. This database is imported and filtered so that the variable “tg” becomes “t4,” which is a dummy variable identifying those treated with t4 versus individuals in the control group. Additionally, the logarithm of the variable “inuidur1” is created.
Penn = pd.read_csv(r'../../../data/penn_jae.csv')
Penn= Penn[(Penn['tg'] == 4) | (Penn['tg'] == 0)]
Penn.update(Penn[Penn['tg'] == 4][['tg']].replace(to_replace=4, value=1))
Penn.rename(columns={'tg': 't4'}, inplace=True)
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Cell In[2], line 1
----> 1 Penn = pd.read_csv(r'../../../data/penn_jae.csv')
2 Penn= Penn[(Penn['tg'] == 4) | (Penn['tg'] == 0)]
3 Penn.update(Penn[Penn['tg'] == 4][['tg']].replace(to_replace=4, value=1))
File ~\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\io\parsers\readers.py:1026, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend)
1013 kwds_defaults = _refine_defaults_read(
1014 dialect,
1015 delimiter,
(...)
1022 dtype_backend=dtype_backend,
1023 )
1024 kwds.update(kwds_defaults)
-> 1026 return _read(filepath_or_buffer, kwds)
File ~\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\io\parsers\readers.py:620, in _read(filepath_or_buffer, kwds)
617 _validate_names(kwds.get("names", None))
619 # Create the parser.
--> 620 parser = TextFileReader(filepath_or_buffer, **kwds)
622 if chunksize or iterator:
623 return parser
File ~\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\io\parsers\readers.py:1620, in TextFileReader.__init__(self, f, engine, **kwds)
1617 self.options["has_index_names"] = kwds["has_index_names"]
1619 self.handles: IOHandles | None = None
-> 1620 self._engine = self._make_engine(f, self.engine)
File ~\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\io\parsers\readers.py:1880, in TextFileReader._make_engine(self, f, engine)
1878 if "b" not in mode:
1879 mode += "b"
-> 1880 self.handles = get_handle(
1881 f,
1882 mode,
1883 encoding=self.options.get("encoding", None),
1884 compression=self.options.get("compression", None),
1885 memory_map=self.options.get("memory_map", False),
1886 is_text=is_text,
1887 errors=self.options.get("encoding_errors", "strict"),
1888 storage_options=self.options.get("storage_options", None),
1889 )
1890 assert self.handles is not None
1891 f = self.handles.handle
File ~\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\io\common.py:873, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
868 elif isinstance(handle, str):
869 # Check whether the filename is to be opened in binary mode.
870 # Binary mode does not support 'encoding' and 'newline'.
871 if ioargs.encoding and "b" not in ioargs.mode:
872 # Encoding
--> 873 handle = open(
874 handle,
875 ioargs.mode,
876 encoding=ioargs.encoding,
877 errors=errors,
878 newline="",
879 )
880 else:
881 # Binary mode
882 handle = open(handle, ioargs.mode)
FileNotFoundError: [Errno 2] No such file or directory: '../../../data/penn_jae.csv'
Penn['dep1'] = (Penn['dep'] == 1).astype(int)
Penn['dep2'] = (Penn['dep'] == 2).astype(int)
Penn['log_inuidur1'] = np.log(Penn['inuidur1'])
Penn.drop('dep', axis=1, inplace=True)
Unnamed: 0 abdt t4 inuidur1 inuidur2 female black hispanic \
0 1 10824 0.0 18 18 0 0 0
3 4 10824 0.0 1 1 0 0 0
4 5 10747 0.0 27 27 0 0 0
11 12 10607 1.0 9 9 0 0 0
12 13 10831 0.0 27 27 0 0 0
othrace q1 ... agelt35 agegt54 durable nondurable lusd husd muld \
0 0 0 ... 0 0 0 0 0 1 0
3 0 0 ... 0 0 0 0 1 0 0
4 0 0 ... 0 0 0 0 1 0 0
11 0 0 ... 1 0 0 0 0 0 1
12 0 0 ... 0 1 1 0 1 0 0
dep1 dep2 log_inuidur1
0 0 1 2.890372
3 0 0 0.000000
4 0 0 3.295837
11 0 0 2.197225
12 1 0 3.295837
[5 rows x 26 columns]
Bootstrap function#
A function is created with the specified linear regression “log(inuidur1)~t4+ (female+black+othrace+dep1+dep2+q2+q3+q4+q5+q6+agelt35+agegt54+durable+lusd+husd),” which outputs information about the estimated coefficients (dep1 and dep2 are dummy variables created from dep; ultimately, it is the same as treating dep as a categorical variable).
def get_estimates(data,index):
A = data[['t4','female', 'black', 'othrace', 'dep1', 'dep2', 'q2', 'q3', 'q4', 'q5', 'q6', 'agelt35', 'agegt54', 'durable', 'lusd', 'husd']]
X= A.iloc[index]
B = Penn['log_inuidur1']
y=B.iloc[index]
lr = LinearRegression()
lr.fit(X,y)
intercept = lr.intercept_
coef = lr.coef_
return [intercept,coef]
def get_indices(data,num_samples):
return np.random.choice(np.arange(Penn.shape[0]), num_samples, replace=True)
n=len(Penn)
def boot(data,func,R):
coeff_1 = []
coeff_2 = []
coeff_3 = []
for i in range(R):
coeff_1.append(func(data,get_indices(data,n))[1][0])
coeff_2.append(func(data,get_indices(data,n))[1][1])
coeff_3.append(func(data,get_indices(data,n))[1][2])
coeff_1_statistics = {'estimated_value':np.mean(coeff_1),'std_error':np.std(coeff_1)}
coeff_2_statistics = {'estimated_value':np.mean(coeff_2),'std_error':np.std(coeff_2)}
coeff_3_statistics = {'estimated_value':np.mean(coeff_3),'std_error':np.std(coeff_3)}
return {'coeff_1_statistics':coeff_1_statistics,'coeff_2_statistics':coeff_2_statistics,'coeff_3_statistics':coeff_3_statistics}, coeff_1, coeff_2,coeff_3
Standard error#
results = boot(Penn,get_estimates,1000)
print('Result for coefficient term t4 ',results[0]['coeff_1_statistics'])
print('Result for coefficient term female',results[0]['coeff_2_statistics'])
print('Result for coefficient term black',results[0]['coeff_3_statistics'])
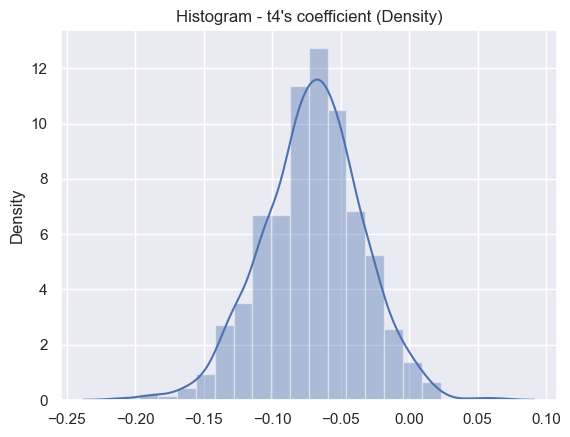
Result for coefficient term t4 {'estimated_value': -0.06988404525587032, 'std_error': 0.03580097798905932}
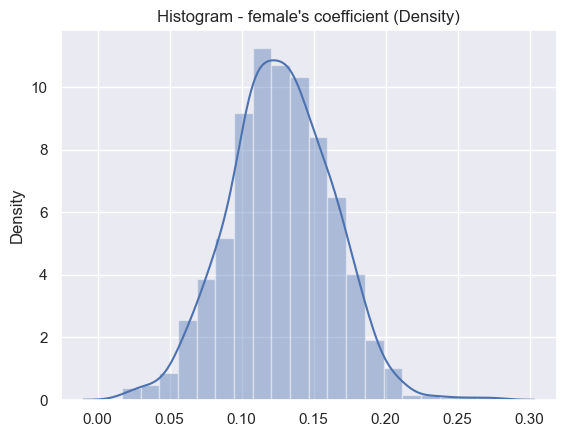
Result for coefficient term female {'estimated_value': 0.12750195812651027, 'std_error': 0.03530038686565401}
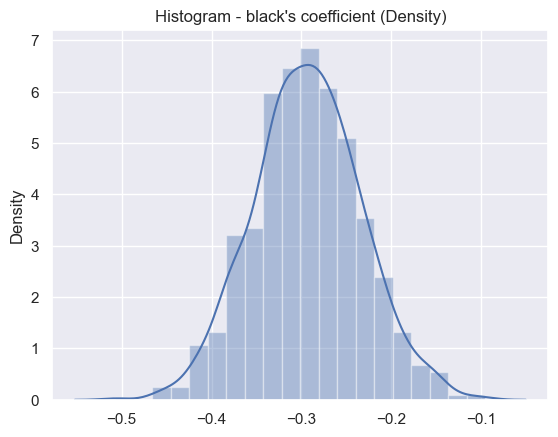
Result for coefficient term black {'estimated_value': -0.2917027856008439, 'std_error': 0.06050929944267628}
data = {
"Variable": ["t4", "female", "black"],
"Estimate": [
results[0]['coeff_1_statistics']['estimated_value'],
results[0]['coeff_2_statistics']['estimated_value'],
results[0]['coeff_3_statistics']['estimated_value']
],
"Standard Error": [
results[0]['coeff_1_statistics']['std_error'],
results[0]['coeff_2_statistics']['std_error'],
results[0]['coeff_3_statistics']['std_error']
]
}
df = pd.DataFrame(data)
print(df)
Variable Estimate Standard Error
0 t4 -0.070467 0.036035
1 female 0.127009 0.035710
2 black -0.293443 0.059621
t4 distribution#
sns.set_theme()
ax = sns.distplot(results[1], bins=20)
plt.title("Histogram - t4's coefficient (Density)")
C:\Users\Erzo\AppData\Local\Temp\ipykernel_13076\562490230.py:2: UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
ax = sns.distplot(results[1], bins=20)
Text(0.5, 1.0, "Histogram - t4's coefficient (Density)")
Female distribution#
sns.set_theme()
ax = sns.distplot(results[2], bins=20)
plt.title("Histogram - female's coefficient (Density)")
C:\Users\Erzo\AppData\Local\Temp\ipykernel_13076\889737210.py:2: UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
ax = sns.distplot(results[2], bins=20)
Text(0.5, 1.0, "Histogram - female's coefficient (Density)")
Black distribution#
sns.set_theme()
ax = sns.distplot(results[3], bins=20)
plt.title("Histogram - black's coefficient (Density)")
C:\Users\Erzo\AppData\Local\Temp\ipykernel_13076\825763745.py:2: UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
ax = sns.distplot(results[3], bins=20)
Text(0.5, 1.0, "Histogram - black's coefficient (Density)")
Causal Forest#
# Libraries
import statistics
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
import statsmodels.formula.api as smf
from scipy.stats import norm
# Causal forest libraries
from econml.grf import RegressionForest
from econml.dml import CausalForestDML
from econml.cate_interpreter import SingleTreeCateInterpreter
1. Preprocessing#
# Import synthetic data from data folder
df = pd.read_csv("../../data/synthetic_data.csv")
df.head()
| schoolid | Z | Y | S3 | C1 | C2 | C3 | XC | X1 | X2 | X3 | X4 | X5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 76 | 1 | 0.081602 | 6 | 4 | 2 | 1 | 4 | 0.334544 | 0.648586 | -1.310927 | 0.224077 | -0.426757 |
| 1 | 76 | 1 | -0.385869 | 4 | 12 | 2 | 1 | 4 | 0.334544 | 0.648586 | -1.310927 | 0.224077 | -0.426757 |
| 2 | 76 | 1 | 0.398184 | 6 | 4 | 2 | 0 | 4 | 0.334544 | 0.648586 | -1.310927 | 0.224077 | -0.426757 |
| 3 | 76 | 1 | -0.175037 | 6 | 4 | 2 | 0 | 4 | 0.334544 | 0.648586 | -1.310927 | 0.224077 | -0.426757 |
| 4 | 76 | 1 | 0.884583 | 6 | 4 | 1 | 0 | 4 | 0.334544 | 0.648586 | -1.310927 | 0.224077 | -0.426757 |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10391 entries, 0 to 10390
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 schoolid 10391 non-null int64
1 Z 10391 non-null int64
2 Y 10391 non-null float64
3 S3 10391 non-null int64
4 C1 10391 non-null int64
5 C2 10391 non-null int64
6 C3 10391 non-null int64
7 XC 10391 non-null int64
8 X1 10391 non-null float64
9 X2 10391 non-null float64
10 X3 10391 non-null float64
11 X4 10391 non-null float64
12 X5 10391 non-null float64
dtypes: float64(6), int64(7)
memory usage: 1.0 MB
# Save school clusters in variable
school_id = df['schoolid'].astype('category').cat.codes
# Create a dummy matrix (one-hot encoding) for school IDs
school_mat = pd.to_numeric(df['schoolid'], errors='coerce')
school_mat = sm.add_constant(pd.get_dummies(df['schoolid'], drop_first=False)).iloc[:, 1:].values
# Calculate the size of each school group
school_size = school_mat.sum(axis=0)
# Fit treatment (w) OLS
formula = 'Z ~ ' + ' + '.join(df.columns.drop(['Z', 'Y']))
w_lm = smf.glm(formula=formula, data=df, family=sm.families.Binomial()).fit()
# Print summary of the GLM model
print(w_lm.summary())
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: Z No. Observations: 10391
Model: GLM Df Residuals: 10379
Model Family: Binomial Df Model: 11
Link Function: Logit Scale: 1.0000
Method: IRLS Log-Likelihood: -6519.5
Date: Thu, 06 Jun 2024 Deviance: 13039.
Time: 20:51:37 Pearson chi2: 1.04e+04
No. Iterations: 4 Pseudo R-squ. (CS): 0.007280
Covariance Type: nonrobust
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -1.0758 0.146 -7.348 0.000 -1.363 -0.789
schoolid -0.0005 0.001 -0.574 0.566 -0.002 0.001
S3 0.1022 0.020 5.233 0.000 0.064 0.141
C1 -0.0023 0.005 -0.431 0.666 -0.013 0.008
C2 -0.0974 0.042 -2.313 0.021 -0.180 -0.015
C3 -0.1378 0.045 -3.050 0.002 -0.226 -0.049
XC 0.0277 0.018 1.568 0.117 -0.007 0.062
X1 -0.0881 0.028 -3.103 0.002 -0.144 -0.032
X2 -0.0004 0.033 -0.011 0.991 -0.066 0.065
X3 0.0337 0.029 1.179 0.239 -0.022 0.090
X4 -0.0201 0.027 -0.738 0.460 -0.074 0.033
X5 0.0082 0.027 0.303 0.762 -0.045 0.062
==============================================================================
In the previous OLS, we can observe that only the ctudent’s self-reported expectations for success (S3), student gender (C2), student first-generation status (C3), and school-level mean of students’ fixed mindsets (X1) variables are significat
# We define T, Y, and X_raw
Y = df['Y']
T = df['Z']
X_raw = df.drop(columns=['schoolid', 'Z', 'Y']) # School ID does not affect pscore
W = None
# Create model matrices for categorical variables
C1_exp = pd.get_dummies(X_raw['C1'], prefix='C1')
XC_exp = pd.get_dummies(X_raw['XC'], prefix='XC')
# Combine these matrices with the rest of the data
X = pd.concat([X_raw.drop(columns=['C1', 'XC']), C1_exp, XC_exp], axis=1)
We have a sample of 10,391 children from 76 schools, and we expand the categorical variables, resulting in 28 covariates, \(X_i \in \mathbb{R}^{28}\)
X
| S3 | C2 | C3 | X1 | X2 | X3 | X4 | X5 | C1_1 | C1_2 | ... | C1_11 | C1_12 | C1_13 | C1_14 | C1_15 | XC_0 | XC_1 | XC_2 | XC_3 | XC_4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 2 | 1 | 0.334544 | 0.648586 | -1.310927 | 0.224077 | -0.426757 | False | False | ... | False | False | False | False | False | False | False | False | False | True |
| 1 | 4 | 2 | 1 | 0.334544 | 0.648586 | -1.310927 | 0.224077 | -0.426757 | False | False | ... | False | True | False | False | False | False | False | False | False | True |
| 2 | 6 | 2 | 0 | 0.334544 | 0.648586 | -1.310927 | 0.224077 | -0.426757 | False | False | ... | False | False | False | False | False | False | False | False | False | True |
| 3 | 6 | 2 | 0 | 0.334544 | 0.648586 | -1.310927 | 0.224077 | -0.426757 | False | False | ... | False | False | False | False | False | False | False | False | False | True |
| 4 | 6 | 1 | 0 | 0.334544 | 0.648586 | -1.310927 | 0.224077 | -0.426757 | False | False | ... | False | False | False | False | False | False | False | False | False | True |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 10386 | 7 | 2 | 1 | 1.185986 | -1.129889 | 1.009875 | 1.005063 | -1.174702 | False | False | ... | False | False | False | False | False | False | False | False | True | False |
| 10387 | 7 | 2 | 1 | 1.185986 | -1.129889 | 1.009875 | 1.005063 | -1.174702 | False | False | ... | False | False | False | False | False | False | False | False | True | False |
| 10388 | 2 | 1 | 1 | 1.185986 | -1.129889 | 1.009875 | 1.005063 | -1.174702 | False | False | ... | False | False | False | False | True | False | False | False | True | False |
| 10389 | 5 | 1 | 1 | 1.185986 | -1.129889 | 1.009875 | 1.005063 | -1.174702 | False | False | ... | False | False | False | False | False | False | False | False | True | False |
| 10390 | 5 | 2 | 1 | 1.185986 | -1.129889 | 1.009875 | 1.005063 | -1.174702 | True | False | ... | False | False | False | False | False | False | False | False | True | False |
10391 rows × 28 columns
For each sample \(i\), the authors consider potential outcomes \(Y_i(0)\) and \(Y_i(1)\), representing the outcomes if the \(i\)-th sample had been assigned to control \((W_i=0)\) or treatment \((W_i=1)\), respectively. We assume that we observe \(Y_i = Y_i(W_i)\). The average treatment effect is defined as \(\tau = \mathbb{E} [Y_i(1) - Y_i(0)]\), and the conditional average treatment effect function is \(\tau(x) = \mathbb{E} [Y_i(1) - Y_i(0) \mid X_i = x]\).
2. Causal Forest estimation and results#
2.1. Causal Forest#
When using random forests, the authors aim to perform a non-parametric random effects modeling approach, where each school is presumed to influence the student’s outcome. However, the authors do not impose any assumptions about the distribution of these effects, specifically avoiding the assumption that school effects are Gaussian or additive.
The causal forest (CF) method attempts to find neighbourhoods in the covariate space, also known as recursive partitioning. While a random forest is built from decision trees, a causal forest is built from causal trees, where the causal trees learn a low-dimensional representation of treatment effect heterogeneity. To built a CF, we use the post-treatment outcome vector (\(Y\)), the treatment vector (\(T\)), and the 28 parameters matrix (\(X\)).
np.random.seed(123)
forest_model = CausalForestDML(model_t=RegressionForest(),
model_y=RegressionForest(),
n_estimators=200,
min_samples_leaf=4,
max_depth=50,
verbose=0,
random_state=123)
tree_model = forest_model.fit(Y, T, X=X, W=W)
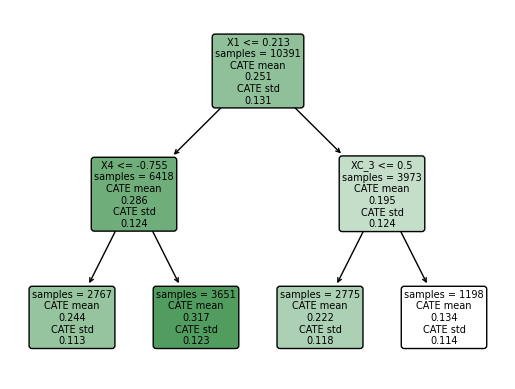
intrp = SingleTreeCateInterpreter(max_depth=2).interpret(forest_model, X)
intrp.plot(feature_names=X.columns, fontsize=7)
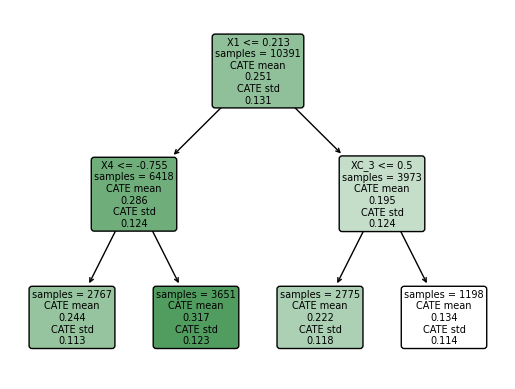
We found that the greater CATE is in the group of students that attendts to a school with a mean fixed mindset level lower than 0.21 (that means, with larger values of growth mindset), and with a percentage of students who are from families whose incomes fall below the federal poverty line greater than -0.75.
2.2. ATE#
The package dml has a built-in function for average treatment effect estimation. First, we estimate the CATE (\(\hat{\tau}\)), where we can see it is around 0.2 and 0.4. Then, we find that the ATE value is around 0.25.
tau_hat = forest_model.effect(X=X) # tau(X) estimates
statistics.mean(tau_hat)
0.25106325917227695
# Do not use this for assessing heterogeneity. See text above.
sns.displot(tau_hat, stat="density", bins = 10)
plt.title("CATE estimates")
Text(0.5, 1.0, 'CATE estimates')
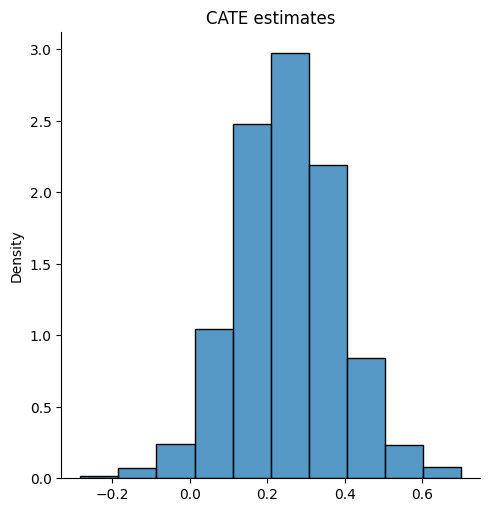
The causal forest CATE estimates exhibit some variation, from -0.2 to 0.6.
2.3. Run best linear predictor analysis#
# Assuming cf is an instance of an EconML estimator
# and tau_hat is the estimated Conditional Average Treatment Effect (CATE)
# Compare regions with high and low estimated CATEs
high_effect = tau_hat > np.median(tau_hat)
# Calculate average treatment effect for high and low effect subsets
ate_high = tree_model.ate_inference(X=X[high_effect])
ate_low = tree_model.ate_inference(X=X[~high_effect])
ate_high
| mean_point | stderr_mean | zstat | pvalue | ci_mean_lower | ci_mean_upper |
|---|---|---|---|---|---|
| 0.355 | 0.122 | 2.906 | 0.004 | 0.115 | 0.594 |
| std_point | pct_point_lower | pct_point_upper |
|---|---|---|
| 0.08 | 0.257 | 0.558 |
| stderr_point | ci_point_lower | ci_point_upper |
|---|---|---|
| 0.146 | 0.079 | 0.669 |
Note: The stderr_mean is a conservative upper bound.
ate_low
| mean_point | stderr_mean | zstat | pvalue | ci_mean_lower | ci_mean_upper |
|---|---|---|---|---|---|
| 0.148 | 0.121 | 1.215 | 0.225 | -0.091 | 0.386 |
| std_point | pct_point_lower | pct_point_upper |
|---|---|---|
| 0.082 | -0.043 | 0.249 |
| stderr_point | ci_point_lower | ci_point_upper |
|---|---|---|
| 0.146 | -0.162 | 0.426 |
Note: The stderr_mean is a conservative upper bound.
# Calculate 95% confidence interval for the difference in ATEs
difference_in_ate = 0.355 - 0.148
ci_width = norm.ppf(0.975) * np.sqrt(0.122**2 + 0.121**2)
print(f"95% CI for difference in ATE: {difference_in_ate:.3f} +/- {ci_width:.3f}")
95% CI for difference in ATE: 0.207 +/- 0.337
# The fitted causal forest model should provide these values:
W_hat = tree_model.propensity_ # Estimated treatment probability (cf$W.hat)
Y_hat = tree_model.predict(X) # Predicted outcome (cf$Y.hat)
# Calculate dr.score
dr_score = (
tau_hat +
W / W_hat * (Y - Y_hat - (1 - W_hat) * tau_hat) -
(1 - W) / (1 - W_hat) * (Y - Y_hat + W_hat * tau_hat)
)
# Calculate school.score
school_score = np.dot(school_mat.T, dr_score) / school_size
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[140], line 2
1 # Calculate school.score
----> 2 school_score = np.dot(school_mat.T, dr_score) / school_size
NameError: name 'dr_score' is not defined
2.4. Look at school-wise heterogeneity#
# Set up plot parameters
plt.rcParams.update({'font.size': 14}) # Adjust the font size
# Create the histogram
plt.figure(figsize=(8, 6))
plt.hist(school_score, bins=30, edgecolor='black')
plt.xlabel('School Treatment Effect Estimate', fontsize=16)
plt.ylabel('Frequency', fontsize=16)
plt.title('')
# Save the plot as a PDF
plt.savefig('school_hist.pdf')
# Close the plot
plt.close()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[142], line 6
4 # Create the histogram
5 plt.figure(figsize=(8, 6))
----> 6 plt.hist(school_score, bins=30, edgecolor='black')
7 plt.xlabel('School Treatment Effect Estimate', fontsize=16)
8 plt.ylabel('Frequency', fontsize=16)
File ~/opt/anaconda3/envs/personal/lib/python3.11/site-packages/matplotlib/pyplot.py:3236, in hist(x, bins, range, density, weights, cumulative, bottom, histtype, align, orientation, rwidth, log, color, label, stacked, data, **kwargs)
3211 @_copy_docstring_and_deprecators(Axes.hist)
3212 def hist(
3213 x: ArrayLike | Sequence[ArrayLike],
(...)
3234 BarContainer | Polygon | list[BarContainer | Polygon],
3235 ]:
-> 3236 return gca().hist(
3237 x,
3238 bins=bins,
3239 range=range,
3240 density=density,
3241 weights=weights,
3242 cumulative=cumulative,
3243 bottom=bottom,
3244 histtype=histtype,
3245 align=align,
3246 orientation=orientation,
3247 rwidth=rwidth,
3248 log=log,
3249 color=color,
3250 label=label,
3251 stacked=stacked,
3252 **({"data": data} if data is not None else {}),
3253 **kwargs,
3254 )
File ~/opt/anaconda3/envs/personal/lib/python3.11/site-packages/matplotlib/__init__.py:1465, in _preprocess_data.<locals>.inner(ax, data, *args, **kwargs)
1462 @functools.wraps(func)
1463 def inner(ax, *args, data=None, **kwargs):
1464 if data is None:
-> 1465 return func(ax, *map(sanitize_sequence, args), **kwargs)
1467 bound = new_sig.bind(ax, *args, **kwargs)
1468 auto_label = (bound.arguments.get(label_namer)
1469 or bound.kwargs.get(label_namer))
File ~/opt/anaconda3/envs/personal/lib/python3.11/site-packages/matplotlib/axes/_axes.py:6834, in Axes.hist(self, x, bins, range, density, weights, cumulative, bottom, histtype, align, orientation, rwidth, log, color, label, stacked, **kwargs)
6830 for xi in x:
6831 if len(xi):
6832 # python's min/max ignore nan,
6833 # np.minnan returns nan for all nan input
-> 6834 xmin = min(xmin, np.nanmin(xi))
6835 xmax = max(xmax, np.nanmax(xi))
6836 if xmin <= xmax: # Only happens if we have seen a finite value.
TypeError: '<' not supported between instances of 'ellipsis' and 'float'
2.5. Analysis ignoring clusters. How do the results change?#
# Assuming you have already defined X, Y, W, selected.idx, Y.hat, and W.hat
# Create a causal forest model
cf_noclust = tree_model(tune_parameters="all")
cf_noclust.fit(X[:, selected.idx], Y, W, Y_hat=Y_hat, W_hat=W_hat)
# Calculate the average treatment effect (ATE)
ATE_noclust = cf_noclust.average_treatment_effect()
# Print the 95% confidence interval for the ATE
print(f"95% CI for the ATE: {round(ATE_noclust[0], 3)} +/- {round(1.96 * ATE_noclust[1], 3)}")
# Test calibration
cf_noclust_copy = cf_noclust.copy()
tau_hat_noclust = cf_noclust_copy.predict(X) # Assuming X is the same as in R
cf_noclust_copy.predictions = tau_hat_noclust
cf_noclust_copy.clusters = school_id
cf_noclust_copy.test_calibration()
# Calculate loss
R_loss = ((Y - Y_hat) - tau_hat * (W - W_hat))**2
R_loss_noclust = ((Y - Y_hat) - tau_hat_noclust * (W - W_hat))**2
R_loss_crossfold = ((Y - Y_hat) - tau_hat_crossfold * (W - W_hat))**2
# Print the differences in loss
print(f"Difference in loss (no clustering): {R_loss_noclust - R_loss}")
print(f"Difference in loss (crossfold): {R_loss_crossfold - R_loss}")
# Summary of ANOVA
# Assuming dr.score and school_id are defined
summary_aov = pd.DataFrame({'dr.score': dr_score, 'school.id': school_id})
2.6. Analysis without fitting the propensity score#
# Create a causal forest model
cf_noprop = CausalForestDML(tune_parameters="all", equalize_cluster_weights=True)
cf_noprop.fit(X[:, selected.idx], Y, W, Y_hat=Y_hat, W_hat=W_hat)
# Calculate the average treatment effect (ATE)
ATE_noprop = cf_noprop.average_treatment_effect()
# Print the 95% confidence interval for the ATE
print(f"95% CI for the ATE: {round(ATE_noprop[0], 3)} +/- {round(1.96 * ATE_noprop[1], 3)}")
# Plot the estimates
plt.figure()
plt.scatter(tau_hat, tau_hat_noprop)
plt.xlim(min(tau_hat), max(tau_hat_noprop))
plt.ylim(min(tau_hat), max(tau_hat_noprop))
plt.xlabel("Orthogonalized causal forest estimates")
plt.ylabel("Non-orthogonalized causal forest")
plt.plot([min(tau_hat), max(tau_hat_noprop)], [min(tau_hat), max(tau_hat_noprop)], linestyle="--", color="gray")
plt.show()
2.7. The code plot six plots in the Make some plots section, so explain what you find there.#
# Calculate the average treatment effect (ATE)
ATE_noprop = statistics.mean(cf_noprop.ate())
# Print the 95% confidence interval for the ATE
print(f"95% CI for the ATE: {round(ATE_noprop[0], 3)} +/- {round(1.96 * ATE_noprop[1], 3)}")
# Plot histograms
plt.figure(figsize=(10, 6))
plt.subplot(221)
plt.hist(tau_hat, bins=25, edgecolor='black')
plt.xlabel("Estimated CATE")
plt.title("Histogram (tau.hat)")
plt.subplot(222)
plt.hist(tau_hat_noprop, bins=25, edgecolor='black')
plt.xlabel("Estimated CATE")
plt.title("Histogram (tau.hat.noprop)")
plt.subplot(223)
plt.hist(tau_hat_noclust, bins=25, edgecolor='black')
plt.xlabel("Estimated CATE")
plt.title("Histogram (tau.hat.noclust)")
# Boxplots vs. X1 and X2
plt.subplot(224)
plt.boxplot(tau_hat, labels=["X1"])
plt.xlabel("X1")
plt.ylabel("Estimated CATE")
plt.title("Boxplot (tau.hat) vs. X1")
plt.tight_layout()
plt.show()
# Plot school-wise average CATE estimate
school_avg_tauhat = (school_mat.T @ tau_hat) / school_size
plt.figure(figsize=(8, 6))
plt.scatter(school_avg_tauhat, school_pred, c='b', s=50)
plt.plot([min(school_avg_tauhat), max(school_pred)], [min(school_avg_tauhat), max(school_pred)], linestyle="--", color="gray")
plt.xlabel("Average CATE estimate in school")
plt.ylabel("School-wise forest predictions")
plt.title("School-wise Average CATE Estimate vs. Predictions")
plt.grid(True)
plt.show()
2.8. Visualize school-level covariates by treatment heterogeneity#
# Standardize school.X
school.X_std = (school.X - school.X.mean()) / school.X.std()
# Create terciles
tercile_bins = [-np.inf, np.quantile(school.pred, 1/3), np.quantile(school.pred, 2/3), np.inf]
school.tercile = pd.cut(school.pred, bins=tercile_bins, labels=["low", "mid", "high"])
# Create a design matrix for terciles
school.tercile_mat = pd.get_dummies(school.tercile, drop_first=True)
# Calculate means
school.means = np.dot(np.linalg.pinv(school.tercile_mat.T @ school.tercile_mat), school.tercile_mat.T @ school.X_std)
# Calculate MM and create color mapping
MM = np.max(np.abs(school.means))
school.col = [HC[1 + round(20 * (0.5 + aa))] for aa in school.means]
# Create a DataFrame for plotting
DF_plot = pd.DataFrame({
'tercile': np.repeat(["low", "mid", "high"], 9),
'mean': school.means.flatten(),
'feature': np.tile(colnames(school.X), 3)
})
# Plot the heatmap
plt.figure(figsize=(8, 4.5))
plt.imshow(DF_plot.pivot(index='tercile', columns='feature', values='mean'),
cmap='coolwarm', aspect='auto', vmin=-MM, vmax=MM)
plt.colorbar(label='Mean')
plt.xticks(range(len(colnames(school.X))), colnames(school.X), rotation=90)
plt.yticks(range(3), ["low", "mid", "high"])
plt.xlabel("Feature")
plt.ylabel("Tercile")
plt.title("Tercile Plot")
plt.tight_layout()
plt.show()
# Calculate mean for XC.3
mean_XC3 = np.mean(school.X['XC.3'])
mean_XC3_low_tercile = np.mean(school.X['XC.3'][school.tercile == "low"])
2.9. CATE by school#
# Order school.pred and then order the indices
ord = np.argsort(np.argsort(school_pred))
school_sort = ord[school_id]
# Create a boxplot and save it to a PDF file
plt.figure(figsize=(10, 8))
plt.boxplot([tau_hat_noclust[school_sort == i] for i in np.unique(school_sort)],
positions=np.unique(school_sort), widths=0.5, patch_artist=True,
boxprops=dict(facecolor='lightblue', color='blue'),
whiskerprops=dict(color='blue', linewidth=1.5),
capprops=dict(color='blue', linewidth=1.5),
medianprops=dict(color='red', linewidth=2),
meanprops=dict(marker='o', markerfacecolor='yellow', markeredgecolor='black', markersize=10))
# Add points for school mean CATE
school_mean_cate = [np.mean(tau_hat_noclust[school_sort == i]) for i in np.unique(school_sort)]
plt.plot(np.unique(school_sort), school_mean_cate, marker='o', color='red', linestyle='None')
# Add points for CATE w/o clustering
plt.plot(np.arange(1, 77), np.sort(school_pred), marker='o', color='green', linestyle='None')
# Labels and legend
plt.xlabel('School', fontsize=16)
plt.ylabel('Estimated CATE', fontsize=16)
plt.xticks(np.unique(school_sort))
plt.legend(['School mean CATE', 'CATE w/o clustering'], loc='upper left', fontsize=12)
# Save the plot to a PDF file
plt.savefig('school_boxplot.pdf')
# Show plot
plt.show()