Lab 1 - R Code#
Math Demonstrations#
1. Prove the Frisch-Waugh-Lovell theorem#
Given the model:
where \(y\) is an \(n \times 1\) vector, \(D\) is an \(n \times k_1\) matrix, \(\beta_1\) is a \(k_1 \times 1\) vector, \(W\) is an \(n \times k_2\) matrix, \(\beta_2\) is a \(k_2 \times 1\) vector, and \(\mu\) is an \(n \times 1\) vector of error terms.
We can construct the following equation:
Running \(y\) on \(W\), we get:
Similarly, running \(D\) on \(W\) gives us:
Running \(\epsilon_y\) on \(\epsilon_D\):
Comparing the original model with this, we can see that:
2. Show that the Conditional Expectation Function minimizes expected squared error#
Given the model:
where \(m(X)\) represents the conditional expectation of \(Y\) on \(X\). Let’s define an arbitrary model:
where \(g(X)\) represents any function of \(X\).
Working with the expected squared error from the arbitrary model:
Using the law of iterated expectations:
Since \(m(X)\) and \(g(X)\) are functions of \(X\), the term \((m(X)-g(X))\) can be thought of as constant when conditioning on \(X\). Thus:
It is important to note that \(E[Y-m(X) \mid X] = 0\) by definition of \(m(X)\), so we get:
Because the second term in the equation is always non-negative, it is clear that the function is minimized when \(g(X)\) equals \(m(X)\). In which case:
Replication 1 - Code#
In the previous lab, we already analyzed data from the March Supplement of the U.S. Current Population Survey (2015) and answered the question how to use job-relevant characteristics, such as education and experience, to best predict wages. Now, we focus on the following inference question:
What is the difference in predicted wages between men and women with the same job-relevant characteristics?
Thus, we analyze if there is a difference in the payment of men and women (gender wage gap). The gender wage gap may partly reflect discrimination against women in the labor market or may partly reflect a selection effect, namely that women are relatively more likely to take on occupations that pay somewhat less (for example, school teaching).
To investigate the gender wage gap, we consider the following log-linear regression model
where \(D\) is the indicator of being female (\(1\) if female and \(0\) otherwise) and the \(W\)’s are controls explaining variation in wages. Considering transformed wages by the logarithm, we are analyzing the relative difference in the payment of men and women.
library(ggplot2)
Data analysis#
We consider the same subsample of the U.S. Current Population Survey (2015) as in the previous lab. Let us load the data set.
load("../../data/wage2015_subsample_inference.Rdata")
dim(data)
- 5150
- 20
Variable description
occ : occupational classification
ind : industry classification
lwage : log hourly wage
sex : gender (1 female) (0 male)
shs : some high school
hsg : High school graduated
scl : Some College
clg: College Graduate
ad: Advanced Degree
ne: Northeast
mw: Midwest
so: South
we: West
exp1: experience
Filtering data to focus on college-advanced-educated workers#
data <- data[data$ad == 1 | data$scl == 1 | data$clg == 1, colnames(data)]
attach(data) # make each variable as an object
Exploratory Data Analysis#
colnames(data)
- 'wage'
- 'lwage'
- 'sex'
- 'shs'
- 'hsg'
- 'scl'
- 'clg'
- 'ad'
- 'mw'
- 'so'
- 'we'
- 'ne'
- 'exp1'
- 'exp2'
- 'exp3'
- 'exp4'
- 'occ'
- 'occ2'
- 'ind'
- 'ind2'
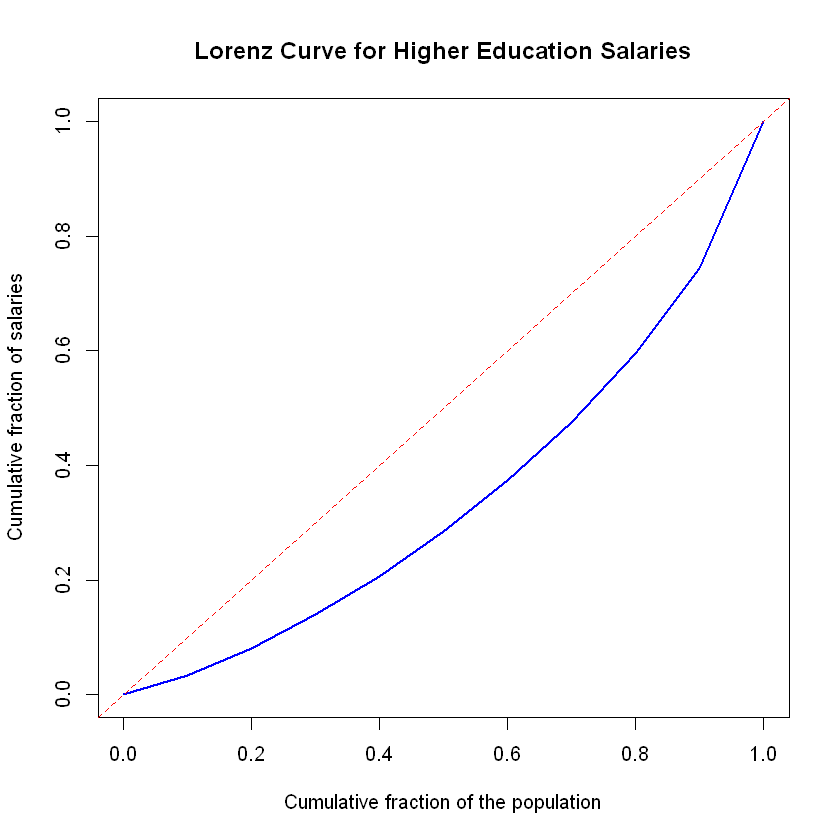
###################### Lorenz Curve for Salaries by Deciles for the subgroup of individuals who accessed higher education ######################
# Sort wages in ascending order
wage_sorted <- sort(wage)
# Compute the cumulative sum of sorted wages
cumulative_sum <- cumsum(wage_sorted)
# Calculate the deciles of the cumulative sum of wages
deciles <- quantile(cumulative_sum, probs = seq(0, 1, by = 0.1))
# Create a vector for the cumulative fraction of the population for x-axis
population_fraction <- seq(0, 1, by = 0.1)
# Calculate the cumulative fraction of salaries
salary_fraction <- quantile(deciles/sum(wage), probs = seq(0, 1, by = 0.1))
# Plot the Lorenz curve
plot(population_fraction, salary_fraction, type = "l", lwd = 2, col = "blue",
main = "Lorenz Curve for Higher Education Salaries",
xlab = "Cumulative fraction of the population",
ylab = "Cumulative fraction of salaries")
abline(0, 1, lty = 2, col = "red") # Equality line
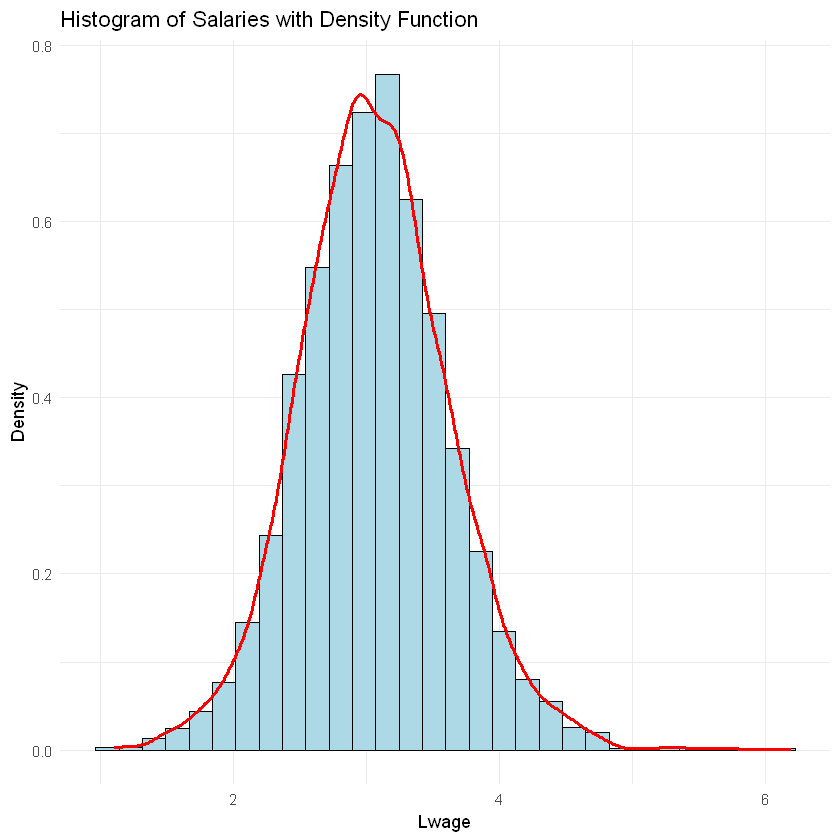
########################### Histogram for lwage ###########################
ggplot(data, aes(x = lwage)) +
geom_histogram(aes(y = ..density..), bins = 30, fill = "lightblue", color = "black") +
geom_density(color = "red", size = 1) +
labs(title = "Histogram of Salaries with Density Function", x = "Lwage", y = "Density") +
theme_minimal()
Warning message:
"Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead."
Warning message:
"The dot-dot notation (`..density..`) was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(density)` instead."
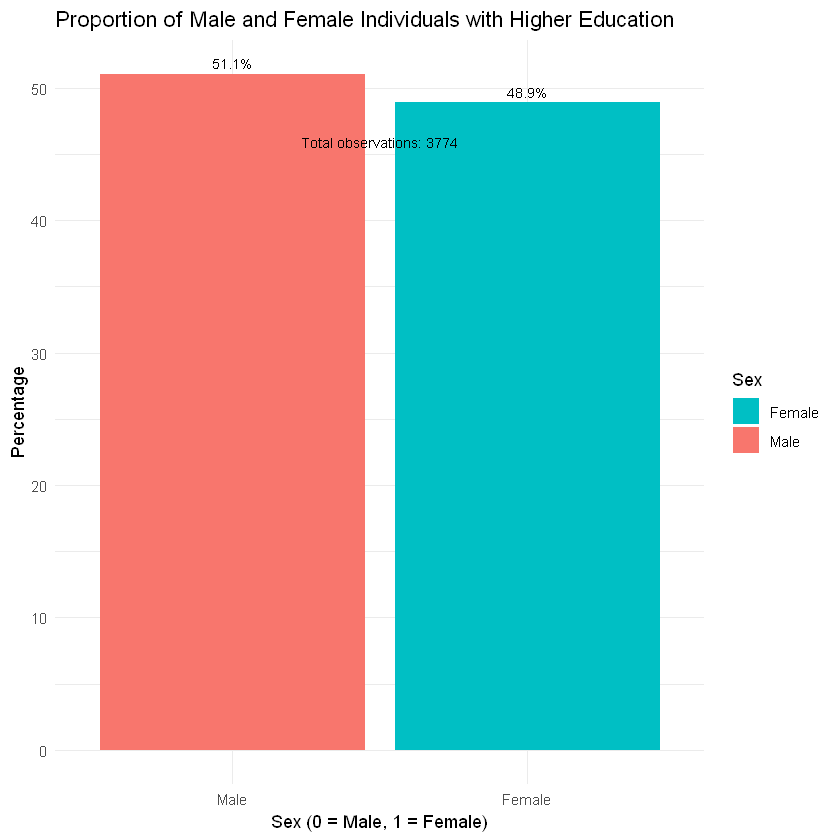
############################Graph bar sex
total_observations <- nrow(data)
proportions <- prop.table(table(data$sex)) * 100
plot_data <- data.frame(sex = factor(names(proportions), labels = c("Male", "Female")), proportion = as.numeric(proportions))
ggplot(plot_data, aes(x = sex, y = proportion, fill = sex)) +
geom_bar(stat = "identity") +
labs(title = "Proportion of Male and Female Individuals with Higher Education",
x = "Sex (0 = Male, 1 = Female)", y = "Percentage",
fill = "Sex") +
theme_minimal() +
geom_text(aes(label = paste0(round(proportion, 1), "%")), vjust = -0.5, size = 3) +
geom_text(aes(x = 1.5, y = max(plot_data$proportion) * 0.9,
label = paste("Total observations:", total_observations)),
hjust = 0.5, size = 3) +
guides(fill = guide_legend(title = "Sex", reverse = TRUE))
Warning message:
"Use of `plot_data$proportion` is discouraged.
ℹ Use `proportion` instead."
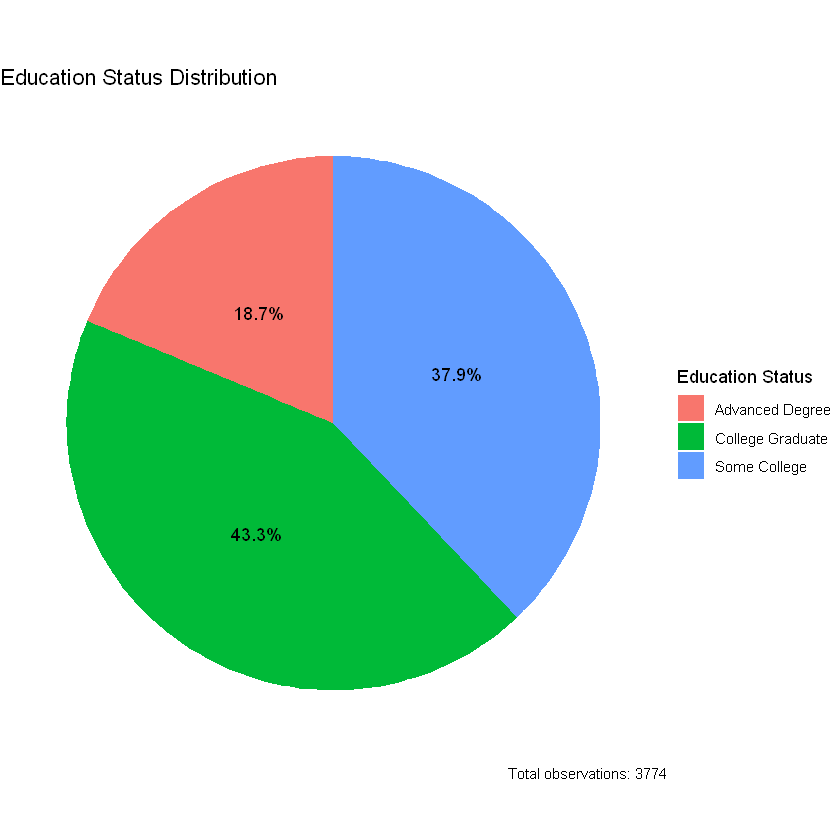
########################Education Status"Analysis of individuals who accessed higher education"
library(dplyr)
library(tidyr)
library(ggplot2)
data <- data %>%
mutate(Education_Status = case_when(
scl == 1 ~ "Some College",
clg == 1 ~ "College Graduate",
ad == 1 ~ "Advanced Degree"
))
edu_freq <- data %>%
count(Education_Status)
total_obs <- sum(edu_freq$n)
edu_freq <- edu_freq %>%
mutate(Percentage = n / total_obs * 100)
# Crear el gráfico de pastel
ggplot(edu_freq, aes(x = "", y = Percentage, fill = Education_Status)) +
geom_bar(stat = "identity", width = 1) +
coord_polar("y", start = 0) +
labs(title = "Education Status Distribution",
x = NULL, y = NULL,
fill = "Education Status",
caption = paste("Total observations:", total_obs)) +
scale_y_continuous(labels = scales::percent_format()) +
geom_text(aes(label = paste0(round(Percentage, 1), "%")), position = position_stack(vjust = 0.5)) +
theme_void() +
theme(legend.position = "right")
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
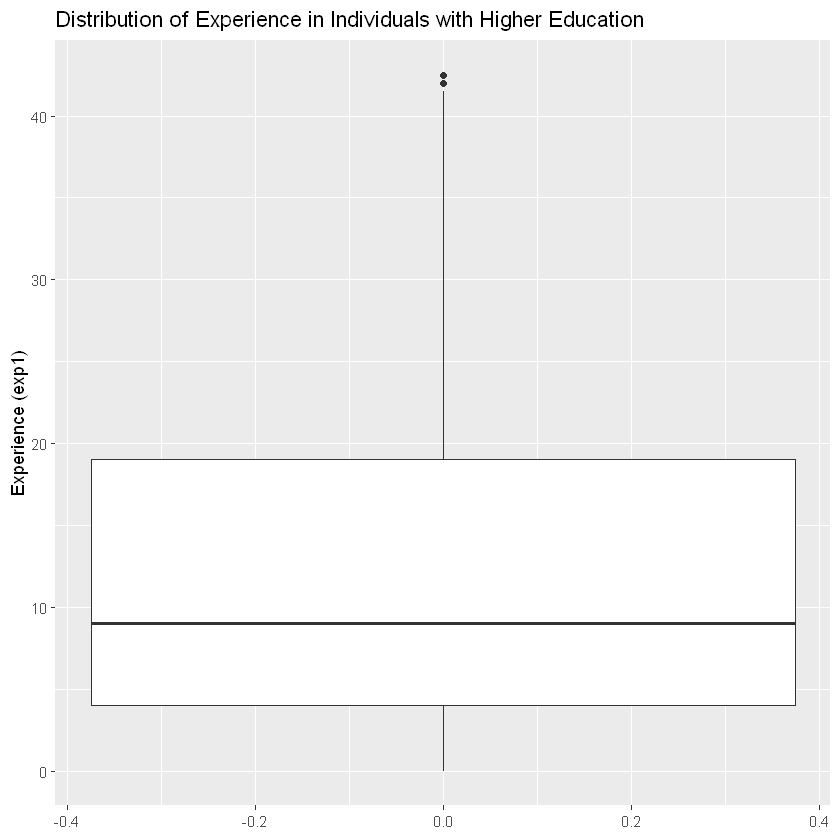
#######################################Experience
ggplot(data, aes(y = exp1)) +
geom_boxplot() +
labs(title = "Distribution of Experience in Individuals with Higher Education",
y = "Experience (exp1)")
To start our (causal) analysis, we compare the sample means given gender:
install.packages("xtable")
library(xtable)
Z <- data[which(colnames(data) %in% c("lwage","sex","shs","hsg","scl","clg","ad","ne","mw","so","we","exp1"))]
data_female <- data[data$sex==1,]
Z_female <- data_female[which(colnames(data) %in% c("lwage","sex","shs","hsg","scl","clg","ad","ne","mw","so","we","exp1"))]
data_male <- data[data$sex==0,]
Z_male <- data_male[which(colnames(data) %in% c("lwage","sex","shs","hsg","scl","clg","ad","ne","mw","so","we","exp1"))]
table <- matrix(0, 12, 3)
table[1:12,1] <- as.numeric(lapply(Z,mean))
table[1:12,2] <- as.numeric(lapply(Z_male,mean))
table[1:12,3] <- as.numeric(lapply(Z_female,mean))
rownames(table) <- c("Log Wage","Sex","Less then High School","High School Graduate","Some College","Gollage Graduate","Advanced Degree", "Northeast","Midwest","South","West","Experience")
colnames(table) <- c("All","Men","Women")
tab<- xtable(table, digits = 4)
tab
Installing package into 'C:/Users/Matias Villalba/AppData/Local/R/win-library/4.3'
(as 'lib' is unspecified)
package 'xtable' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\Matias Villalba\AppData\Local\Temp\Rtmp8WDop2\downloaded_packages
| All | Men | Women | |
|---|---|---|---|
| <dbl> | <dbl> | <dbl> | |
| Log Wage | 3.0627476 | 3.0994485 | 3.0244165 |
| Sex | 0.4891362 | 0.0000000 | 1.0000000 |
| Less then High School | 0.0000000 | 0.0000000 | 0.0000000 |
| High School Graduate | 0.0000000 | 0.0000000 | 0.0000000 |
| Some College | 0.3794383 | 0.4056017 | 0.3521127 |
| Gollage Graduate | 0.4334923 | 0.4362033 | 0.4306609 |
| Advanced Degree | 0.1870694 | 0.1581950 | 0.2172264 |
| Northeast | 0.2498675 | 0.2458506 | 0.2540628 |
| Midwest | 0.2983572 | 0.3034232 | 0.2930661 |
| South | 0.2225755 | 0.2308091 | 0.2139762 |
| West | 0.2291998 | 0.2199170 | 0.2388949 |
| Experience | 12.5102014 | 12.2022822 | 12.8317985 |
print(tab,type="html") # set type="latex" for printing table in LaTeX
<!-- html table generated in R 4.3.3 by xtable 1.8-4 package -->
<!-- Wed Aug 7 21:38:18 2024 -->
<table border=1>
<tr> <th> </th> <th> All </th> <th> Men </th> <th> Women </th> </tr>
<tr> <td align="right"> Log Wage </td> <td align="right"> 3.0627 </td> <td align="right"> 3.0994 </td> <td align="right"> 3.0244 </td> </tr>
<tr> <td align="right"> Sex </td> <td align="right"> 0.4891 </td> <td align="right"> 0.0000 </td> <td align="right"> 1.0000 </td> </tr>
<tr> <td align="right"> Less then High School </td> <td align="right"> 0.0000 </td> <td align="right"> 0.0000 </td> <td align="right"> 0.0000 </td> </tr>
<tr> <td align="right"> High School Graduate </td> <td align="right"> 0.0000 </td> <td align="right"> 0.0000 </td> <td align="right"> 0.0000 </td> </tr>
<tr> <td align="right"> Some College </td> <td align="right"> 0.3794 </td> <td align="right"> 0.4056 </td> <td align="right"> 0.3521 </td> </tr>
<tr> <td align="right"> Gollage Graduate </td> <td align="right"> 0.4335 </td> <td align="right"> 0.4362 </td> <td align="right"> 0.4307 </td> </tr>
<tr> <td align="right"> Advanced Degree </td> <td align="right"> 0.1871 </td> <td align="right"> 0.1582 </td> <td align="right"> 0.2172 </td> </tr>
<tr> <td align="right"> Northeast </td> <td align="right"> 0.2499 </td> <td align="right"> 0.2459 </td> <td align="right"> 0.2541 </td> </tr>
<tr> <td align="right"> Midwest </td> <td align="right"> 0.2984 </td> <td align="right"> 0.3034 </td> <td align="right"> 0.2931 </td> </tr>
<tr> <td align="right"> South </td> <td align="right"> 0.2226 </td> <td align="right"> 0.2308 </td> <td align="right"> 0.2140 </td> </tr>
<tr> <td align="right"> West </td> <td align="right"> 0.2292 </td> <td align="right"> 0.2199 </td> <td align="right"> 0.2389 </td> </tr>
<tr> <td align="right"> Experience </td> <td align="right"> 12.5102 </td> <td align="right"> 12.2023 </td> <td align="right"> 12.8318 </td> </tr>
</table>
| All | Men | Women | |
|---|---|---|---|
| Log Wage | 3.0627 | 3.0994 | 3.0244 |
| Sex | 0.4891 | 0.0000 | 1.0000 |
| Less then High School | 0.0000 | 0.0000 | 0.0000 |
| High School Graduate | 0.0000 | 0.0000 | 0.0000 |
| Some College | 0.3794 | 0.4056 | 0.3521 |
| Gollage Graduate | 0.4335 | 0.4362 | 0.4307 |
| Advanced Degree | 0.1871 | 0.1582 | 0.2172 |
| Northeast | 0.2499 | 0.2459 | 0.2541 |
| Midwest | 0.2984 | 0.3034 | 0.2931 |
| South | 0.2226 | 0.2308 | 0.2140 |
| West | 0.2292 | 0.2199 | 0.2389 |
| Experience | 12.5102 | 12.2023 | 12.8318 |
In particular, the table above shows that the difference in average logwage between men and women is equal to \(0,075\)
mean(data_female$lwage)-mean(data_male$lwage)
Thus, the unconditional gender wage gap is about \(7,5\)% for the group of never married workers (women get paid less on average in our sample). We also observe that never married working women are relatively more educated than working men and have lower working experience.
This unconditional (predictive) effect of gender equals the coefficient \(\beta\) in the univariate ols regression of \(Y\) on \(D\):
We verify this by running an ols regression in R.
#install.packages("sandwich")
library(sandwich)
nocontrol.fit <- lm(lwage ~ sex, data = data)
nocontrol.est <- summary(nocontrol.fit)$coef["sex",1]
HCV.coefs <- vcovHC(nocontrol.fit, type = 'HC');
nocontrol.se <- sqrt(diag(HCV.coefs))[2] # Estimated std errors
# print unconditional effect of gender and the corresponding standard error
cat ("The estimated gender coefficient is",nocontrol.est," and the corresponding robust standard error is",nocontrol.se)
The estimated gender coefficient is -0.07503201 and the corresponding robust standard error is 0.0183426
Note that the standard error is computed with the R package sandwich to be robust to heteroskedasticity.
Next, we run an ols regression of \(Y\) on \((D,W)\) to control for the effect of covariates summarized in \(W\):
Here, we are considering the flexible model from the previous lab. Hence, \(W\) controls for experience, education, region, and occupation and industry indicators plus transformations and two-way interactions.
Let us run the ols regression with controls.
# Ols regression with controls
flex <- lwage ~ sex + (exp1+exp2+exp3+exp4)*(shs+hsg+scl+clg+occ2+ind2+mw+so+we)
# Note that ()*() operation in formula objects in R creates a formula of the sort:
# (exp1+exp2+exp3+exp4)+ (shs+hsg+scl+clg+occ2+ind2+mw+so+we) + (exp1+exp2+exp3+exp4)*(shs+hsg+scl+clg+occ2+ind2+mw+so+we)
# This is not intuitive at all, but that's what it does.
control.fit <- lm(flex, data=data)
control.est <- summary(control.fit)$coef[2,1]
summary(control.fit)
cat("Coefficient for OLS with controls", control.est)
HCV.coefs <- vcovHC(control.fit, type = 'HC');
control.se <- sqrt(diag(HCV.coefs))[2] # Estimated std errors
Call:
lm(formula = flex, data = data)
Residuals:
Min 1Q Median 3Q Max
-1.88469 -0.28018 -0.00257 0.27071 2.87358
Coefficients: (11 not defined because of singularities)
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.880838 0.463424 8.374 < 2e-16 ***
sex -0.067634 0.017476 -3.870 0.000111 ***
exp1 -0.108571 0.182969 -0.593 0.552963
exp2 2.760461 2.185329 1.263 0.206608
exp3 -1.557529 0.928441 -1.678 0.093518 .
exp4 0.245175 0.125503 1.954 0.050834 .
shs NA NA NA NA
hsg NA NA NA NA
scl -0.268071 0.128942 -2.079 0.037689 *
clg -0.044201 0.071314 -0.620 0.535423
occ22 0.148912 0.134319 1.109 0.267660
occ23 0.151683 0.173250 0.876 0.381353
occ24 0.024109 0.189196 0.127 0.898608
occ25 -0.435165 0.197117 -2.208 0.027333 *
occ26 -0.220077 0.195436 -1.126 0.260207
occ27 0.283226 0.198407 1.427 0.153525
occ28 -0.224300 0.174748 -1.284 0.199380
occ29 -0.331892 0.172040 -1.929 0.053792 .
occ210 0.009382 0.166232 0.056 0.954997
occ211 -0.574719 0.340497 -1.688 0.091522 .
occ212 -0.132992 0.265391 -0.501 0.616320
occ213 -0.267986 0.251119 -1.067 0.285968
occ214 0.230008 0.373618 0.616 0.538182
occ215 -0.172214 0.276890 -0.622 0.534008
occ216 -0.124377 0.154234 -0.806 0.420058
occ217 -0.430457 0.144865 -2.971 0.002984 **
occ218 -0.186069 2.225178 -0.084 0.933364
occ219 -0.081721 0.392145 -0.208 0.834932
occ220 -0.454853 0.259208 -1.755 0.079383 .
occ221 -0.809969 0.254915 -3.177 0.001499 **
occ222 -0.815933 0.360786 -2.262 0.023786 *
ind23 -1.089541 0.743919 -1.465 0.143120
ind24 0.044558 0.502874 0.089 0.929399
ind25 -0.547942 0.471498 -1.162 0.245261
ind26 -0.718493 0.472438 -1.521 0.128394
ind27 -0.408055 0.537482 -0.759 0.447785
ind28 -0.661250 0.515152 -1.284 0.199365
ind29 -0.756120 0.461846 -1.637 0.101684
ind210 -0.529993 0.531342 -0.997 0.318608
ind211 -0.972449 0.482059 -2.017 0.043741 *
ind212 -0.729268 0.458956 -1.589 0.112156
ind213 -0.998945 0.516806 -1.933 0.053326 .
ind214 -0.612478 0.450779 -1.359 0.174325
ind215 -0.543112 0.631890 -0.860 0.390121
ind216 -0.553484 0.476666 -1.161 0.245657
ind217 -0.838034 0.460336 -1.820 0.068770 .
ind218 -0.791949 0.459071 -1.725 0.084594 .
ind219 -0.928112 0.490880 -1.891 0.058745 .
ind220 -0.899239 0.484704 -1.855 0.063646 .
ind221 -0.777590 0.475908 -1.634 0.102368
ind222 -0.443536 0.467122 -0.950 0.342427
mw 0.140500 0.086958 1.616 0.106244
so 0.026207 0.079301 0.330 0.741058
we 0.048288 0.088297 0.547 0.584493
exp1:shs NA NA NA NA
exp1:hsg NA NA NA NA
exp1:scl -0.071528 0.044794 -1.597 0.110395
exp1:clg -0.052510 0.031659 -1.659 0.097290 .
exp1:occ22 -0.066435 0.053768 -1.236 0.216692
exp1:occ23 -0.039714 0.067203 -0.591 0.554593
exp1:occ24 -0.044148 0.080037 -0.552 0.581264
exp1:occ25 0.130869 0.090981 1.438 0.150402
exp1:occ26 -0.036843 0.079519 -0.463 0.643162
exp1:occ27 -0.217129 0.081806 -2.654 0.007986 **
exp1:occ28 -0.043218 0.069581 -0.621 0.534564
exp1:occ29 0.020649 0.071375 0.289 0.772366
exp1:occ210 0.014178 0.066700 0.213 0.831675
exp1:occ211 0.037333 0.126451 0.295 0.767830
exp1:occ212 -0.055604 0.100191 -0.555 0.578947
exp1:occ213 0.041249 0.091958 0.449 0.653774
exp1:occ214 -0.119023 0.133471 -0.892 0.372585
exp1:occ215 -0.066657 0.103520 -0.644 0.519678
exp1:occ216 -0.020584 0.058149 -0.354 0.723375
exp1:occ217 0.021233 0.053788 0.395 0.693043
exp1:occ218 -0.066422 1.110702 -0.060 0.952317
exp1:occ219 -0.073559 0.135324 -0.544 0.586763
exp1:occ220 0.079898 0.090445 0.883 0.377082
exp1:occ221 0.270508 0.091179 2.967 0.003030 **
exp1:occ222 0.077255 0.120728 0.640 0.522271
exp1:ind23 0.434498 0.300512 1.446 0.148306
exp1:ind24 0.004614 0.190028 0.024 0.980629
exp1:ind25 0.178890 0.187530 0.954 0.340186
exp1:ind26 0.234188 0.185514 1.262 0.206897
exp1:ind27 0.095699 0.212425 0.451 0.652373
exp1:ind28 0.223093 0.216341 1.031 0.302512
exp1:ind29 0.147902 0.181455 0.815 0.415077
exp1:ind210 0.154391 0.204641 0.754 0.450630
exp1:ind211 0.329852 0.189314 1.742 0.081533 .
exp1:ind212 0.287189 0.182027 1.578 0.114717
exp1:ind213 0.360734 0.197746 1.824 0.068201 .
exp1:ind214 0.188209 0.178995 1.051 0.293114
exp1:ind215 0.112956 0.282951 0.399 0.689764
exp1:ind216 0.104720 0.189077 0.554 0.579716
exp1:ind217 0.206963 0.182375 1.135 0.256526
exp1:ind218 0.204515 0.181267 1.128 0.259291
exp1:ind219 0.199490 0.192716 1.035 0.300669
exp1:ind220 0.152476 0.189062 0.806 0.420018
exp1:ind221 0.250721 0.186934 1.341 0.179932
exp1:ind222 0.163191 0.183004 0.892 0.372597
exp1:mw -0.047600 0.035164 -1.354 0.175932
exp1:so -0.013572 0.031634 -0.429 0.667917
exp1:we -0.036068 0.034310 -1.051 0.293222
exp2:shs NA NA NA NA
exp2:hsg NA NA NA NA
exp2:scl 0.687115 0.481881 1.426 0.153985
exp2:clg 0.402346 0.390598 1.030 0.303044
exp2:occ22 0.527094 0.609392 0.865 0.387125
exp2:occ23 0.225955 0.762662 0.296 0.767040
exp2:occ24 0.609598 0.948693 0.643 0.520547
exp2:occ25 -1.603297 1.212946 -1.322 0.186313
exp2:occ26 0.064776 0.949165 0.068 0.945594
exp2:occ27 3.099522 0.997912 3.106 0.001911 **
exp2:occ28 0.260534 0.797301 0.327 0.743861
exp2:occ29 0.172604 0.829760 0.208 0.835228
exp2:occ210 -0.349280 0.775901 -0.450 0.652622
exp2:occ211 -0.145738 1.423343 -0.102 0.918452
exp2:occ212 0.424348 1.149393 0.369 0.712006
exp2:occ213 -0.742081 0.992571 -0.748 0.454730
exp2:occ214 0.265853 1.401494 0.190 0.849561
exp2:occ215 0.338227 1.128005 0.300 0.764313
exp2:occ216 -0.001585 0.642063 -0.002 0.998030
exp2:occ217 -0.353390 0.589074 -0.600 0.548606
exp2:occ218 -0.038852 9.385632 -0.004 0.996697
exp2:occ219 0.972485 1.399603 0.695 0.487208
exp2:occ220 -0.726862 0.934768 -0.778 0.436865
exp2:occ221 -3.285748 0.977012 -3.363 0.000779 ***
exp2:occ222 -0.456725 1.212919 -0.377 0.706530
exp2:ind23 -5.824070 3.732976 -1.560 0.118810
exp2:ind24 -1.889540 2.229469 -0.848 0.396757
exp2:ind25 -3.397191 2.238534 -1.518 0.129206
exp2:ind26 -3.761806 2.205929 -1.705 0.088223 .
exp2:ind27 -2.099423 2.555966 -0.821 0.411484
exp2:ind28 -3.028965 2.733447 -1.108 0.267889
exp2:ind29 -2.788142 2.167615 -1.286 0.198432
exp2:ind210 -2.990458 2.369136 -1.262 0.206939
exp2:ind211 -4.732148 2.248906 -2.104 0.035431 *
exp2:ind212 -4.133344 2.180238 -1.896 0.058065 .
exp2:ind213 -4.917856 2.310394 -2.129 0.033358 *
exp2:ind214 -3.257135 2.150783 -1.514 0.130015
exp2:ind215 -2.291289 3.277340 -0.699 0.484516
exp2:ind216 -2.200558 2.256437 -0.975 0.329510
exp2:ind217 -3.236968 2.184221 -1.482 0.138435
exp2:ind218 -3.472941 2.170142 -1.600 0.109615
exp2:ind219 -3.089987 2.273999 -1.359 0.174286
exp2:ind220 -2.877686 2.236664 -1.287 0.198319
exp2:ind221 -3.985898 2.224415 -1.792 0.073237 .
exp2:ind222 -3.054599 2.178721 -1.402 0.160999
exp2:mw 0.405157 0.404326 1.002 0.316386
exp2:so 0.169620 0.359140 0.472 0.636745
exp2:we 0.566872 0.383896 1.477 0.139864
exp3:shs NA NA NA NA
exp3:hsg NA NA NA NA
exp3:scl -0.225675 0.194444 -1.161 0.245877
exp3:clg -0.105850 0.169919 -0.623 0.533362
exp3:occ22 -0.127358 0.250141 -0.509 0.610682
exp3:occ23 -0.050120 0.313891 -0.160 0.873148
exp3:occ24 -0.284498 0.394622 -0.721 0.470995
exp3:occ25 0.714085 0.554332 1.288 0.197764
exp3:occ26 0.078209 0.410734 0.190 0.848996
exp3:occ27 -1.394062 0.438136 -3.182 0.001476 **
exp3:occ28 -0.009171 0.328256 -0.028 0.977714
exp3:occ29 -0.158800 0.345751 -0.459 0.646054
exp3:occ210 0.233391 0.326016 0.716 0.474107
exp3:occ211 -0.034816 0.598743 -0.058 0.953634
exp3:occ212 0.017275 0.479540 0.036 0.971265
exp3:occ213 0.342360 0.389837 0.878 0.379888
exp3:occ214 0.144255 0.526802 0.274 0.784230
exp3:occ215 0.007181 0.451462 0.016 0.987310
exp3:occ216 0.104163 0.260350 0.400 0.689117
exp3:occ217 0.188664 0.237170 0.795 0.426388
exp3:occ218 0.081058 1.827773 0.044 0.964629
exp3:occ219 -0.430058 0.540351 -0.796 0.426151
exp3:occ220 0.246731 0.361135 0.683 0.494518
exp3:occ221 1.334641 0.386355 3.454 0.000558 ***
exp3:occ222 0.126481 0.458203 0.276 0.782535
exp3:ind23 2.678306 1.724974 1.553 0.120593
exp3:ind24 1.298272 0.937883 1.384 0.166367
exp3:ind25 1.760362 0.948790 1.855 0.063626 .
exp3:ind26 1.868851 0.933498 2.002 0.045362 *
exp3:ind27 1.174466 1.101602 1.066 0.286431
exp3:ind28 1.234915 1.248416 0.989 0.322640
exp3:ind29 1.468577 0.921405 1.594 0.111060
exp3:ind210 1.575305 0.987705 1.595 0.110821
exp3:ind211 2.233491 0.952335 2.345 0.019068 *
exp3:ind212 1.939677 0.927217 2.092 0.036516 *
exp3:ind213 2.222883 0.968253 2.296 0.021747 *
exp3:ind214 1.673783 0.916531 1.826 0.067902 .
exp3:ind215 1.289902 1.319644 0.977 0.328407
exp3:ind216 1.252572 0.955306 1.311 0.189884
exp3:ind217 1.595382 0.928153 1.719 0.085724 .
exp3:ind218 1.762369 0.923761 1.908 0.056495 .
exp3:ind219 1.526045 0.958381 1.592 0.111403
exp3:ind220 1.527794 0.943682 1.619 0.105543
exp3:ind221 1.936016 0.942996 2.053 0.040141 *
exp3:ind222 1.610296 0.923435 1.744 0.081279 .
exp3:mw -0.127201 0.168242 -0.756 0.449664
exp3:so -0.063505 0.147260 -0.431 0.666318
exp3:we -0.253221 0.155667 -1.627 0.103893
exp4:shs NA NA NA NA
exp4:hsg NA NA NA NA
exp4:scl 0.024112 0.025867 0.932 0.351324
exp4:clg 0.008900 0.023652 0.376 0.706728
exp4:occ22 0.005612 0.033502 0.168 0.866982
exp4:occ23 0.003462 0.041930 0.083 0.934193
exp4:occ24 0.037319 0.052491 0.711 0.477148
exp4:occ25 -0.102265 0.080051 -1.277 0.201511
exp4:occ26 -0.021559 0.057425 -0.375 0.707360
exp4:occ27 0.191216 0.061456 3.111 0.001877 **
exp4:occ28 -0.009269 0.043780 -0.212 0.832338
exp4:occ29 0.027119 0.046596 0.582 0.560597
exp4:occ210 -0.042185 0.044457 -0.949 0.342732
exp4:occ211 0.013254 0.082312 0.161 0.872089
exp4:occ212 -0.030339 0.065220 -0.465 0.641828
exp4:occ213 -0.049296 0.049838 -0.989 0.322675
exp4:occ214 -0.040130 0.064519 -0.622 0.533992
exp4:occ215 -0.015901 0.059245 -0.268 0.788415
exp4:occ216 -0.026793 0.034541 -0.776 0.437990
exp4:occ217 -0.030840 0.031263 -0.986 0.323972
exp4:occ218 NA NA NA NA
exp4:occ219 0.056633 0.068595 0.826 0.409075
exp4:occ220 -0.029161 0.046086 -0.633 0.526935
exp4:occ221 -0.173879 0.050263 -3.459 0.000548 ***
exp4:occ222 -0.015582 0.057468 -0.271 0.786293
exp4:ind23 -0.390159 0.263692 -1.480 0.139069
exp4:ind24 -0.218162 0.125715 -1.735 0.082764 .
exp4:ind25 -0.263027 0.128018 -2.055 0.039990 *
exp4:ind26 -0.274877 0.125734 -2.186 0.028868 *
exp4:ind27 -0.181914 0.151703 -1.199 0.230553
exp4:ind28 -0.149228 0.183833 -0.812 0.416987
exp4:ind29 -0.222289 0.124579 -1.784 0.074458 .
exp4:ind210 -0.237585 0.132035 -1.799 0.072039 .
exp4:ind211 -0.322195 0.128532 -2.507 0.012230 *
exp4:ind212 -0.277952 0.125403 -2.216 0.026723 *
exp4:ind213 -0.311492 0.129616 -2.403 0.016304 *
exp4:ind214 -0.250871 0.124081 -2.022 0.043268 *
exp4:ind215 -0.204839 0.170066 -1.204 0.228488
exp4:ind216 -0.199306 0.128748 -1.548 0.121703
exp4:ind217 -0.234727 0.125392 -1.872 0.061297 .
exp4:ind218 -0.262904 0.125149 -2.101 0.035735 *
exp4:ind219 -0.224314 0.128925 -1.740 0.081968 .
exp4:ind220 -0.235229 0.126946 -1.853 0.063968 .
exp4:ind221 -0.281403 0.127276 -2.211 0.027102 *
exp4:ind222 -0.246069 0.124575 -1.975 0.048315 *
exp4:mw 0.012197 0.022784 0.535 0.592452
exp4:so 0.006360 0.019596 0.325 0.745551
exp4:we 0.033250 0.020541 1.619 0.105598
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4726 on 3539 degrees of freedom
Multiple R-squared: 0.3447, Adjusted R-squared: 0.3013
F-statistic: 7.954 on 234 and 3539 DF, p-value: < 2.2e-16
Coefficient for OLS with controls -0.0676339
The estimated regression coefficient \(\beta_1\approx-0.0676\) measures how our linear prediction of wage changes if we set the gender variable \(D\) from 0 to 1, holding the controls \(W\) fixed. We can call this the predictive effect (PE), as it measures the impact of a variable on the prediction we make. Overall, we see that the unconditional wage gap of size \(4\)% for women increases to about \(7\)% after controlling for worker characteristics.
Next, we are using the Frisch-Waugh-Lovell theorem from the lecture partialling-out the linear effect of the controls via ols.
# Partialling-Out using ols
# models
flex.y <- lwage ~ (exp1+exp2+exp3+exp4)*(shs+hsg+scl+clg+occ2+ind2+mw+so+we) # model for Y
flex.d <- sex ~ (exp1+exp2+exp3+exp4)*(shs+hsg+scl+clg+occ2+ind2+mw+so+we) # model for D
# partialling-out the linear effect of W from Y
t.Y <- lm(flex.y, data=data)$res
# partialling-out the linear effect of W from D
t.D <- lm(flex.d, data=data)$res
# regression of Y on D after partialling-out the effect of W
partial.fit <- lm(t.Y~t.D)
partial.est <- summary(partial.fit)$coef[2,1]
cat("Coefficient for D via partialling-out", partial.est)
# standard error
HCV.coefs <- vcovHC(partial.fit, type = 'HC')
partial.se <- sqrt(diag(HCV.coefs))[2]
# confidence interval
confint(partial.fit)[2,]
Coefficient for D via partialling-out -0.0676339
- 2.5 %
- -0.100823033855121
- 97.5 %
- -0.0344447624332549
Again, the estimated coefficient measures the linear predictive effect (PE) of \(D\) on \(Y\) after taking out the linear effect of \(W\) on both of these variables. This coefficient equals the estimated coefficient from the ols regression with controls.
We know that the partialling-out approach works well when the dimension of \(W\) is low in relation to the sample size \(n\). When the dimension of \(W\) is relatively high, we need to use variable selection or penalization for regularization purposes.
In the following, we illustrate the partialling-out approach using lasso instead of ols.
Next, we summarize the results.
table<- matrix(0, 3, 2)
table[1,1]<- nocontrol.est
table[1,2]<- nocontrol.se
table[2,1]<- control.est
table[2,2]<- control.se
table[3,1]<- partial.est
table[3,2]<- partial.se
colnames(table)<- c("Estimate","Std. Error")
rownames(table)<- c("Without controls", "full reg", "partial reg")
tab<- xtable(table, digits=c(3, 3, 4))
tab
| Estimate | Std. Error | |
|---|---|---|
| <dbl> | <dbl> | |
| Without controls | -0.07503201 | 0.01834260 |
| full reg | -0.06763390 | 0.01676536 |
| partial reg | -0.06763390 | 0.01676536 |
print(tab, type="html")
<!-- html table generated in R 4.3.3 by xtable 1.8-4 package -->
<!-- Wed Aug 7 21:38:19 2024 -->
<table border=1>
<tr> <th> </th> <th> Estimate </th> <th> Std. Error </th> </tr>
<tr> <td align="right"> Without controls </td> <td align="right"> -0.075 </td> <td align="right"> 0.0183 </td> </tr>
<tr> <td align="right"> full reg </td> <td align="right"> -0.068 </td> <td align="right"> 0.0168 </td> </tr>
<tr> <td align="right"> partial reg </td> <td align="right"> -0.068 </td> <td align="right"> 0.0168 </td> </tr>
</table>
| Estimate | Std. Error | |
|---|---|---|
| Without controls | -0.075 | 0.0183 |
| full reg | -0.068 | 0.0168 |
| partial reg | -0.068 | 0.0168 |
##################################################COEF PLOT
library(coefplot)
library(gridExtra)
flex.y <- lwage ~ (exp1+exp2+exp3+exp4)*(scl+clg+ad+occ2+ind2+mw+so+we) # model for Y
flex.d <- sex ~ (exp1+exp2+exp3+exp4)*(scl+clg+ad+occ2+ind2+mw+so+we) # model for D
# partialling-out the linear effect of W from Y
t.Y <- lm(flex.y, data1=data1)$res
# partialling-out the linear effect of W from D
t.D <- lm(flex.d, data1=data1)$res
# Ajustar los modelos
nocontrol.fit <- lm(lwage ~ sex)
control.fit <- lm(lwage ~ sex + (exp1+exp2+exp3+exp4)*(scl+clg+ad+occ2+ind2+mw+so+we))
partial.fit <- lm(t.Y ~ t.D)
# Graficar los coeficientes estimados con límites en el eje x ajustados
plot_nocontrol <- coefplot(nocontrol.fit, coefficients = "sex")+labs(title = "No Controls") + xlim(-0.15, 0)
plot_control <- coefplot(control.fit, coefficients = "sex")+labs(title = "Controls") + xlim(-0.15, 0)
plot_partial <- coefplot(partial.fit, coefficients = "t.D")+labs(title = "Partialling out") + xlim(-0.15, 0)
# Unir los gráficos verticalmente
combined_plot <- grid.arrange(plot_nocontrol, plot_control, plot_partial, nrow = 3)
Attaching package: 'gridExtra'
The following object is masked from 'package:dplyr':
combine
Warning message:
"In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
extra argument 'data1' will be disregarded"
Warning message:
"In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
extra argument 'data1' will be disregarded"
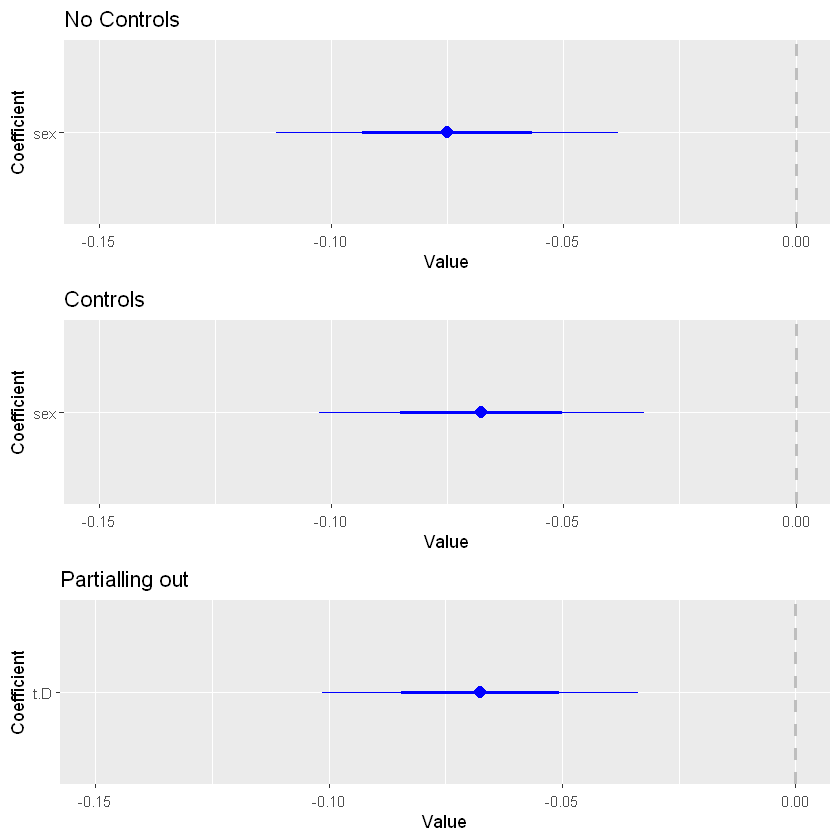
The coefficient associated with the gender variable, which indicates the prediction of being female on salary, is initially negative. This suggests that, on average, women have lower salaries than men. However, after adding these controls, such as work experience or educational level, the negative coefficient associated with the gender variable becomes less negative.
This change in the gender coefficient could be explained by the fact that the control variables are capturing some of the variability in salaries that was previously incorrectly attributed to gender. This suggests that additional factors, beyond gender, are influencing salaries, and the impact of gender on salaries is less pronounced once these other variables are taken into account. Besides, both FWL and including control variables in the regression model yield coefficient estimates for the variable of interest that reflect its net impact on the dependent variable, once the effects of other explanatory variables have been taken into account.
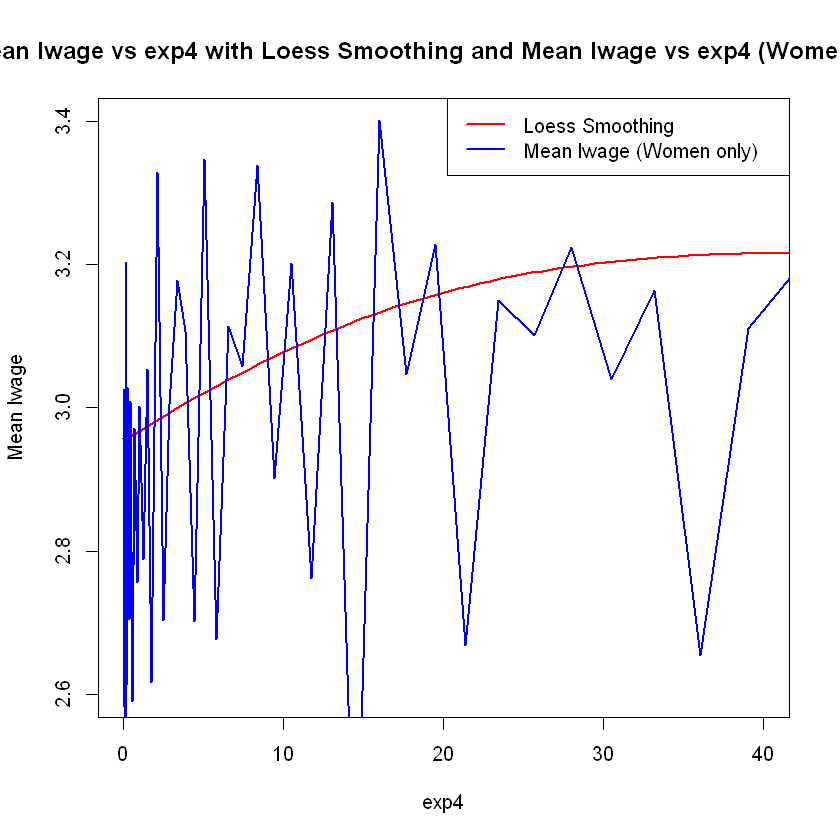
# Generar valores de exp4 para predecir las medias de lwage con más puntos
exp4_seq <- seq(min(data$exp4), max(data$exp4), length.out = 500)
# Ajustar el modelo LOESS
loess_model <- loess(lwage ~ (exp4 + sex), data = data, span = 0.9)
# Crear un nuevo data frame con los valores de exp4 para predecir
new_data <- data.frame(exp4 = exp4_seq, sex = 1)
# Predecir las medias de lwage utilizando el modelo loess
lwage_mean_pred <- predict(loess_model, newdata = new_data)
# Calcula la media de lwage para cada valor único de exp4 solo para mujeres
mean_lwage_women <- tapply(subset(data, sex == 1)$lwage, subset(data, sex == 1)$exp4, mean)
# Graficar ambas relaciones en un solo gráfico
plot(exp4_seq, lwage_mean_pred,
type = "l", # Tipo de gráfico: línea
col = "red", # Color de la línea para el modelo LOESS
lwd = 2, # Grosor de la línea para el modelo LOESS
xlab = "exp4",
ylab = "Mean lwage",
main = "Mean lwage vs exp4 with Loess Smoothing and Mean lwage vs exp4 (Women only)",
xlim = c(0, 40), # Limitar los valores en el eje x de 0 a 40
ylim = c(2.6, 3.4)) # Ajustar la escala del eje y de 2 a 4
lines(as.numeric(names(mean_lwage_women)), mean_lwage_women, col = "blue", lwd = 2) # Agregar la relación de media de lwage vs exp4
legend("topright", legend = c("Loess Smoothing", "Mean lwage (Women only)"), col = c("red", "blue"), lty = 1, lwd = 2)
Warning message in simpleLoess(y, x, w, span, degree = degree, parametric = parametric, :
"pseudoinverse used at -0.10036 -0.010002"
Warning message in simpleLoess(y, x, w, span, degree = degree, parametric = parametric, :
"neighborhood radius 4.8847"
Warning message in simpleLoess(y, x, w, span, degree = degree, parametric = parametric, :
"reciprocal condition number 2.6408e-15"
Warning message in simpleLoess(y, x, w, span, degree = degree, parametric = parametric, :
"There are other near singularities as well. 410.95"
# Generar valores de exp4 para predecir las medias de lwage con más puntos
exp4_seq <- seq(min(data$exp4), max(data$exp4), length.out = 500)
# Ajustar el modelo LOESS
loess_model_men <- loess(lwage ~ (exp4 + sex), data = data, span = 0.9)
# Crear un nuevo data frame con los valores de exp4 para predecir
new_data_men <- data.frame(exp4 = exp4_seq, sex = 0) # Solo varones
# Predecir las medias de lwage utilizando el modelo loess para varones
lwage_mean_pred_men <- predict(loess_model_men, newdata = new_data_men)
# Calcula la media de lwage para cada valor único de exp4 solo para varones
mean_lwage_men <- tapply(subset(data, sex == 0)$lwage, subset(data, sex == 0)$exp4, mean)
# Graficar ambas relaciones en un solo gráfico
plot(exp4_seq, lwage_mean_pred_men,
type = "l", # Tipo de gráfico: línea
col = "red", # Color de la línea para el modelo LOESS
lwd = 2, # Grosor de la línea para el modelo LOESS
xlab = "exp4",
ylab = "Mean lwage",
main = "Mean lwage vs exp4 with Loess Smoothing and Mean lwage vs exp4 (Men only)",
xlim = c(0, 40), # Limitar los valores en el eje x de 0 a 40
ylim = c(2.6, 3.4)) # Ajustar la escala del eje y de 2 a 4
lines(as.numeric(names(mean_lwage_men)), mean_lwage_men, col = "blue", lwd = 2) # Agregar la relación de media de lwage vs exp4 para varones
legend("topright", legend = c("Loess Smoothing", "Mean lwage (Men only)"), col = c("red", "blue"), lty = 1, lwd = 2)
Warning message in simpleLoess(y, x, w, span, degree = degree, parametric = parametric, :
"pseudoinverse used at -0.10036 -0.010002"
Warning message in simpleLoess(y, x, w, span, degree = degree, parametric = parametric, :
"neighborhood radius 4.8847"
Warning message in simpleLoess(y, x, w, span, degree = degree, parametric = parametric, :
"reciprocal condition number 2.6408e-15"
Warning message in simpleLoess(y, x, w, span, degree = degree, parametric = parametric, :
"There are other near singularities as well. 410.95"
Next we try “extra” flexible model, where we take interactions of all controls, giving us about 1000 controls.
extraflex <- lwage ~ sex + (exp1+exp2+exp3+exp4+shs+hsg+scl+clg+occ2+ind2+mw+so+we)^2
control.fit <- lm(extraflex, data=data)
#summary(control.fit)
control.est <- summary(control.fit)$coef[2,1]
cat("Number of Extra-Flex Controls", length(control.fit$coef)-1, "\n")
cat("Coefficient for OLS with extra flex controls", control.est)
#summary(control.fit)
HCV.coefs <- vcovHC(control.fit, type = 'HC');
n= length(wage); p =length(control.fit$coef);
control.se <- sqrt(diag(HCV.coefs))[2]*sqrt(n/(n-p)) # Estimated std errors
# crude adjustment for the effect of dimensionality on OLS standard errors, motivated by Cattaneo, Jannson, and Newey (2018)
# for really correct way of doing this, we need to implement Cattaneo, Jannson, and Newey (2018)'s procedure.
Number of Extra-Flex Controls 979
Coefficient for OLS with extra flex controls -0.05950266
Cross-Validation in Lasso Regression - Manual Implementation Task#
install.packages("ggplot2")
Warning message:
"package 'ggplot2' is in use and will not be installed"
library(caret)
Loading required package: lattice
1. Data Preparation
Load the March Supplement of the U.S. Current Population Survey, year 2015. (wage2015_subsample_inference.Rdata)
load("..\..\data\wage2015_subsample_inference.csv")
# Print a summary of the data frame
print("Summary of the data:")
summary(data)
# Print dimensions of the data frame
print("Dimensions of the data:")
dim(data)
Error: '\.' is an unrecognized escape in character string (<text>:1:10)
Traceback:
flex <- lwage ~ sex + shs + hsg + scl + clg + occ2 + ind2 + mw + so + we +
(exp1 + exp2 + exp3 + exp4) * (shs + hsg + scl + clg + occ2 + ind2 + mw + so + we)
# Fit the model using lm() function for OLS regression
flex_results <- lm(flex, data=data)
summary(flex_results)
# Get exogenous variables from the flexible model
X <- model.matrix(flex_results)
# Set endogenous variable
y <- data$lwage # Directly from the data frame
# Alternatively, extracting response variable from the model object
y_model <- model.response(model.frame(flex_results))
# Verify the contents
head(X) # Shows the first few rows of the model matrix
head(y) # Shows the first few values of the response variable
set.seed(24) # For reproducibility
# Calculate the number of observations to split on
n <- nrow(X)
train_size <- floor(0.8 * n)
# Randomly sample indices for the training data
train_indices <- sample(seq_len(n), size = train_size)
# Create training and test datasets
X_train <- X[train_indices, , drop = FALSE]
X_test <- X[-train_indices, , drop = FALSE]
y_train <- y[train_indices]
y_test <- y[-train_indices]
# Calculate the mean and standard deviation from the training set
train_mean <- apply(X_train, 2, mean)
train_sd <- apply(X_train, 2, sd)
# Standardize the training data
X_train_scaled <- sweep(X_train, 2, train_mean, FUN = "-")
X_train_scaled <- sweep(X_train_scaled, 2, train_sd, FUN = "/")
# Standardize the test data using the same mean and standard deviation as calculated from the training set
X_test_scaled <- sweep(X_test, 2, train_mean, FUN = "-")
X_test_scaled <- sweep(X_test_scaled, 2, train_sd, FUN = "/")
# Check the results of scaling
head(X_train_scaled)
head(X_test_scaled)
2. Define a Range of Alpha (Lambda in our equation) Values
We create a list or array of alpha values to iterate over. These will be the different regularization parameters we test. We started testing from 0.1 to 0.5 and found that the MSE in cross-validation was reducing when the alpha value was incrementing. Therefore, we tried with higher values.
alphas <- seq(0.1, 0.5, by = 0.1)
3. Partition the Dataset for k-Fold Cross-Validation
We divide the dataset into 5 subsets (or folds). Since we are working with a regression task (predicting the log of wage), we use the K-Fold cross-validator from sklearn. We ensure the data is shuffled by adding ‘shuffle=True’ and set a random state for a reproducible output.
set.seed(24) # Set the random seed for reproducibility
# Create a K-fold cross-validation object
kf <- createFolds(y = 1:nrow(X_train), k = 5, list = TRUE, returnTrain = FALSE)
4. Lasso Regression Implementation
Implement a function to fit a Lasso Regression model given a training dataset and an alpha value. The function should return the model’s coefficients and intercept.
lasso_regression <- function(X_train, y_train, alpha, iterations=100, learning_rate=0.01) {
# Get the dimensions of the training data
m <- nrow(X_train)
n <- ncol(X_train)
# Initialize weights (coefficients) and bias (intercept)
W <- matrix(0, nrow = n, ncol = 1) # Coefficients
b <- 0 # Intercept
# Perform gradient descent
for (i in 1:iterations) {
Y_pred <- X_train %*% W + b # Predicted values
dW <- matrix(0, nrow = n, ncol = 1) # Initialize gradient of weights
for (j in 1:n) {
if (W[j, 1] > 0) {
dW[j, 1] <- (-2 * sum(X_train[, j] * (y_train - Y_pred)) + alpha) / m
} else {
dW[j, 1] <- (-2 * sum(X_train[, j] * (y_train - Y_pred)) - alpha) / m
}
}
db <- -2 * sum(y_train - Y_pred) / m # Gradient of bias
# Update weights and bias using gradient descent
W <- W - learning_rate * dW
b <- b - learning_rate * db
}
# Return weights (coefficients) and bias (intercept)
return(list(W = W, b = b))
}
5. Cross-Validation Loop and 6. Selection of Optimal Alpha
We immplement a for loop to fit the lasso regression. Also, we find the best value of alpha that reduces the average MSE for each fold.
# Cross-validation function to calculate average MSE for given alpha values
cross_validate_lasso <- function(X_train, y_train, alphas, kf, iterations=100, learning_rate=0.01) {
avg_mse_values <- numeric(length(alphas))
min_avg_mse <- Inf
best_alpha <- NULL
for (i in seq_along(alphas)) {
alpha <- alphas[i]
mse_list <- numeric(kf$n)
for (fold in 1:kf$n) {
train_index <- kf$inFold[[fold]]
val_index <- kf$outFold[[fold]]
X_train_fold <- X_train[train_index, ]
X_val_fold <- X_train[val_index, ]
y_train_fold <- y_train[train_index]
y_val_fold <- y_train[val_index]
# Train Lasso regression model with the current alpha
model <- lasso_regression(X_train_fold, y_train_fold, alpha, iterations, learning_rate)
W <- model$W
b <- model$b
# Make predictions on validation set
y_pred_val <- X_val_fold %*% W + b
# Calculate MSE for this fold
mse_fold <- mean((y_val_fold - y_pred_val)^2)
mse_list[fold] <- mse_fold
}
# Calculate average MSE across all folds
avg_mse <- mean(mse_list)
avg_mse_values[i] <- avg_mse
cat(sprintf("Alpha=%.1f, Average MSE: %.5f\n", alpha, avg_mse))
# Update best alpha and minimum average MSE
if (avg_mse < min_avg_mse) {
min_avg_mse <- avg_mse
best_alpha <- alpha
}
}
cat(sprintf("Best Alpha: %.1f, Minimum Average MSE: %.5f\n", best_alpha, min_avg_mse))
# Plotting the cross-validated MSE for each alpha value
plot(alphas, avg_mse_values, type = "o", pch = 19, lty = 1, col = "blue",
xlab = "Alpha", ylab = "Average MSE",
main = "Cross-Validated MSE for Different Alpha Values",
xlim = range(alphas), ylim = range(avg_mse_values),
xaxt = "n")
axis(1, at = alphas, labels = alphas)
grid()
}
# Perform cross-validated Lasso regression
cross_validate_lasso(X_train, y_train, alphas, kf, iterations = 100, learning_rate = 0.01)
7. Model Training and Evaluation
# Make predictions on test data
y_pred <- X_test %*% W + b
lasso_corr <- cor(y_test, y_pred)
lasso_mae <- mean(abs(y_test - y_pred))
lasso_mse <- mean((y_test - y_pred)^2)
# Print results
cat(sprintf("Correlation: %.4f\n", lasso_corr))
cat(sprintf("MAE: %.4f\n", lasso_mae))
cat(sprintf("MSE: %.4f\n", lasso_mse))
8. Report Results
We began by selecting the parameters for a flexible model, one that includes interactions. After selecting the parameters, we found that the alpha value that produced the lowest mean squared error (MSE) in cross-validation was 60. We then trained the model using all the available training data with the best alpha value. Using the fitted betas, we predicted the lwage using the test X vector. The resulting MSE in the test data was 0.3569, which was lower than in the training data (which was 0.41906). This indicates that the model is not overfitting and that we have found a good correlation score (R square) of 50%.